Database First Development
March 23, 2021
⚠ The site no longer uses database first development and instead uses simple file based routing with a couple of utility functions. I still think database first development is a cool idea but I don't look at my blog codebase very often and file based routing is much easier to maintain.
This site is an exercise in database first development for blogging. All of the pages in the site are parsed and stored in a sqlite database. The site is then statically generated by querying the database using graphql.
Why would you build a site like this?
I love to organize my thoughts in nested hierarchies and clusters 1. Some people are definitely not obsessed with hierarchies, categories, tags, and clusters 2, but if you are then you may have been frustrated with some of the JAMStack3 frameworks that have become popular recently.
If you every tried building nested sections and page hierarchy in Gatsby or Next.js you'll know what I mean. Both the default gatsby starter and the default next starter have a single folder of posts. If you want to add sections or page organization based on the file system you need to write your own api which is easier said than done. Essentially you have Javascript and Markup but no API for your content.
Previous static site generators exist on the opposite side of the spectrum, thy have rich content APIs but no javascript. Hugo's API supports content organization with nested sections, leaves, categories, and tags out of the box. Unfortunately Hugo's API is quite difficult to use in practice. Even though Hugo's API is simple, Hugo pages are customized with a weird template language which uses hard to read prefix expressions.
Database first development brings the rich content organization of frameworks like Hugo into the new and fun react static blogging ecosystem. The result is a very performant, clean, and intuitive API over your content which you can use to make beautiful web experiences.
If we want to get the parent of the current we simply access the currentPage.parent. If we want to get all the child pages we can access currentPage.pages. Any relationship we encode in the database is just a query away. We could go even further, parse the markdown AST while creating the database, and encode a table of Links with target and source pages. The link table would enable a trivial implementation for rendering backlinks and references. We could even use this table to find broken links in our site. Treating the database as a source of truth is powerful ✨.
Why wouldn't you build a site like this?
All this power does not come for free. Sure I could simply put my posts in a database and call it a day, but instead I use
- prisma to create a sql schema
- typegraphql-prisma to create a graphql schema
- apollo-server to serve a graphql api endpoint
- graphql-code-generator to generate typescript types from graphql queries
- Next.js to statically generate all my pages from this for a static site.
All of these dependencies could break and I'm sure they would be annoying to fix. But hey we're having fun... right? In addition, I would never bring any of this to a production site. As soon as you need to query at runtime the automatically generated apis and type safety lead to a bunch of performance issues. Luckily with a blog all my assets are statically generated so the performance issues are not a problem4.
If you have ideas about what you would like to do or see in a database first blog, let me know on twitter @lukesmurray.
Footnotes
-
Notably Jess Fraz's Blog which is amazing but is simply a list! ↩
-
JAMstack stands for Javascript, Apis, and Markup. The idea is that you handle dynamic rendering with javascript, query your data with APIs, and write your content with markup. ↩
-
Check it out 😉, but don't get too excited.
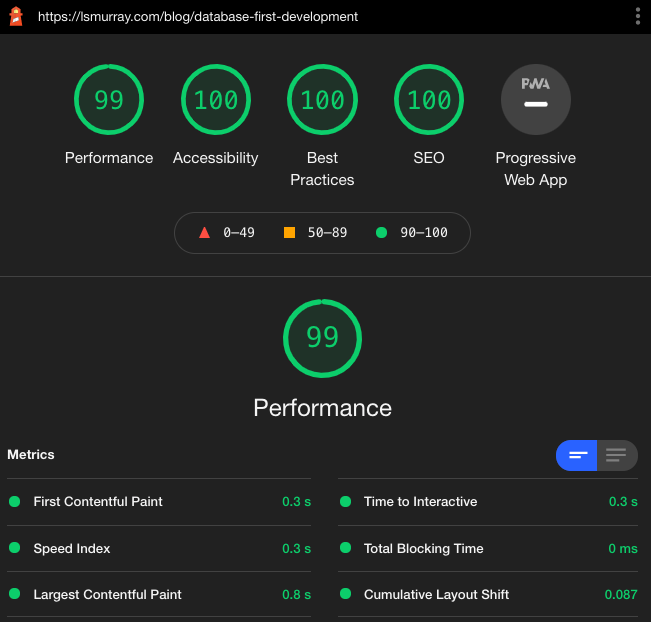 ↩
↩